
ARCHER versions
A number of versions have been widely used for research on the history of English. ARCHER 1 dates from 1993, ARCHER 2 from 2004-5. ARCHER 3.1 was completed in summer 2006. The current version is known as ARCHER 3.2 and was completed in 2013.
blank
ARCHER 3.1
ARCHER 3.1 was coordinated at Heidelberg from 2004 to 2008 by Marianne Hundt (now in Zurich) and Nadja Nesselhauf. It incorporated a partial clean-up and correction of many files and deletion of duplicate files. The materials of ARCHER 3.1 became accessible to the consortium in summer 2006 with
- a new labelling system for filenames (see below),
- convenient distribution formats, e.g. separate folders for each genre-period-variety combination (955 files in 80 folders) or all in one folder,
- revised word counts,
- a suggested protocol for future compilation of texts.
The corpus was made up as follows.
Text categories and filenames
- Eight genres: d = drama, f = fiction, h = sermons, j = journal or diaries, m = medicine, n = news, s = science, x = letters.
- Seven periods: 2 = 1650-99, 3 = 1700-49, 4 = 1750-99, 5 = 1800-49, 6 = 1850-99, 7 = 1900-49, 8 = 1950-99.
- Two varieties: b = British, a = American.
NB. There will be eleven genres and eight periods in ARCHER 3.2.
Filenames were consistently 8+dot+3 characters (always lower case), according to the formula nnnnabcd.gpv, where
- nnnn = year
- abcd = abbreviation of author’s surname (usually first four letters)
- g = genre (abbreviations as shown)
- p = period
- v = variety
For example, the file 1650penn.j2b is a text written in 1650 by William Penn, is a journal, belongs to the period 1650-99, and is British. (The naming convention has been transparently altered in version 3.2 so that the extension becomes part of the filename, e.g. 1650penn_j2b.) All files in version 3.1 were date-stamped as 31 July 2006 03:10.
Word count (British English texts)
| d | f | h | j | m | n | s | x | total | ||
|---|---|---|---|---|---|---|---|---|---|---|
| 1650-99 | 2 | 26,648 | 41,512 | 11,146 | 21,374 | 23,117 | 22,292 | 21,441 | 12,659 | 180,189 |
| 1700-49 | 3 | 25,177 | 44,021 | 10,664 | 21,443 | 21,936 | 21,612 | 20,780 | 12,093 | 177,726 |
| 1750-99 | 4 | 23,962 | 45,056 | 11,068 | 21,843 | 21,003 | 23,087 | 20,565 | 12,091 | 178,675 |
| 1800-49 | 5 | 26,267 | 44,946 | 11,089 | 21,740 | 20,278 | 22,903 | 20,994 | 12,576 | 180,793 |
| 1850-99 | 6 | 26,469 | 43,289 | 10,953 | 22,686 | 22,143 | 23,066 | 21,715 | 10,705 | 181,026 |
| 1900-49 | 7 | 23,048 | 45,274 | 10,569 | 22,066 | 20,204 | 21,975 | 21,337 | 12,434 | 176,907 |
| 1950-99 | 8 | 24,450 | 45,095 | 10,190 | 22,225 | 20,794 | 22,920 | 21,308 | 11,259 | 178,241 |
| total: | 176,021 | 309,193 | 75,679 | 153,377 | 149,475 | 157,855 | 148,140 | 83,817 | 1,253,557 |
Word count (American English texts)
| d | f | h | j | m | n | s | x | total | ||
|---|---|---|---|---|---|---|---|---|---|---|
| 1750-99 | 4 | 27,331 | 42,417 | 10,987 | 22,109 | 23,433 | 22,271 | 20,664 | 11,056 | 180,268 |
| 1850-99 | 6 | 24,214 | 44,224 | 10,740 | 22,534 | 20,424 | 21,992 | 21,326 | 11,253 | 176,707 |
| 1950-99 | 8 | 23,810 | 44,214 | 10,123 | 22,131 | 22,473 | 23,072 | 21,343 | 11,611 | 178,777 |
| total: | 75,355 | 130,855 | 31,850 | 66,774 | 66,330 | 67,335 | 63,333 | 33,920 | 535,752 |
For more information on ARCHER 3.1, see the CoRD entry for ARCHER.
ARCHER 3.2
The current phase of the project, ARCHER 3.2, is intended to enhance the usefulness of the corpus in a number of ways over the period 2008-11 and continuing 2011-13. For the first time, searches can be carried out over the internet. David Denison and Nuria Yáñez-Bouza are coordinating the work being carried out in the international consortium. We had a British Academy Small Research Grant from 1 June 2010 to 31 December 2011 (extended to 1 June 2012) to help fund some of the work at Manchester. For a graphic summary of improvements, see Nuria Yáñez-Bouza’s poster (PDF, 195 KB) (based on that presented at ICAME 32 and now updated to October 2013).
Text categories and filenames
- Twelve genres: a = advertising, d = drama, f = fiction, h = sermons, j = journals, l = legal, m = medicine, n = news, p = early prose, s = science, x = letters, y = diaries.
- Eight periods: 1 = 1600-49, 2 = 1650-99, 3 = 1700-49, 4 = 1750-99, 5 = 1800-49, 6 = 1850-99, 7 = 1900-49, 8 = 1950-99.
- Two varieties: b = British, a = American.
The four extra genres in this version result from the separation of diaries and (travel/political) journals, a special classification ‘early prose’, plus the addition of advertising and legal texts.
Filenames are consistently 8+underscore+3 characters (always lower case), according to the formula nnnnabcd_gpv, where
nnnn = year
abcd = abbreviation of author’s surname (usually first four letters)
g = genre (abbreviations as shown)
p = period
v = variety
For example, the file 1650penn_j2b is a text written in 1650 by William Penn, is a journal, belongs to the period 1650-99, and is British.
Word counts
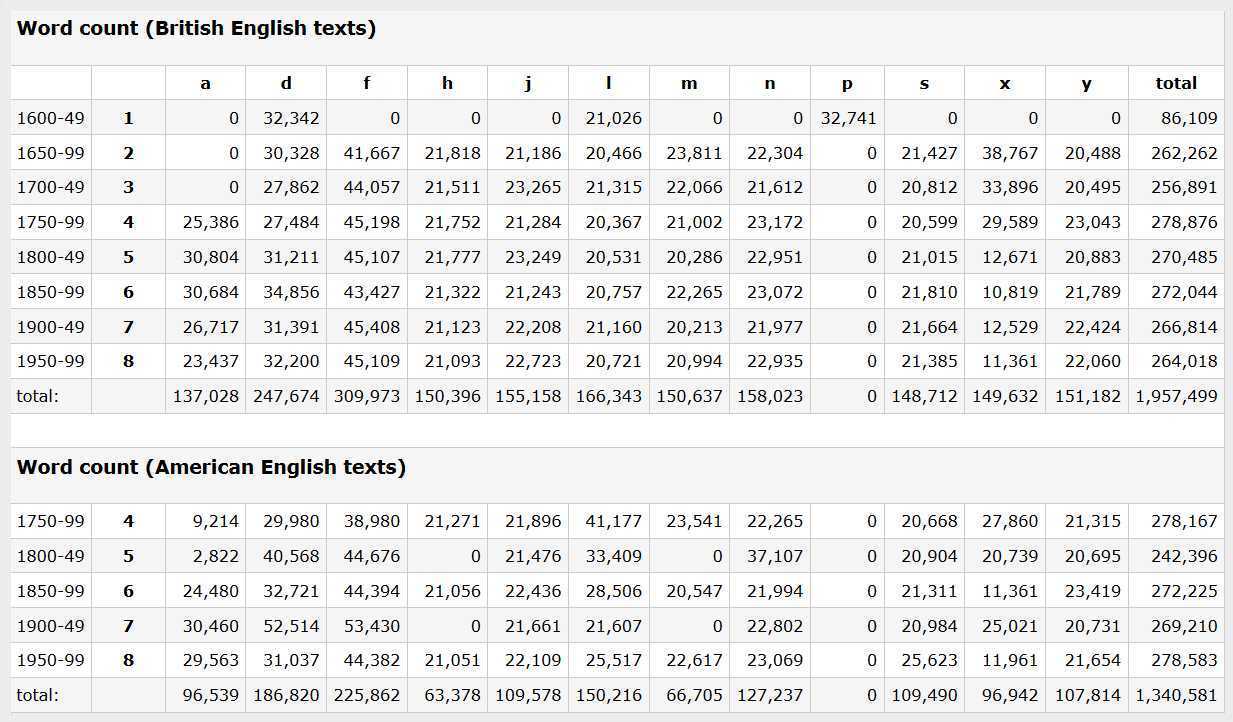
- Two tables of British and American English texts classified by genre and period (JPEG, 122 KB)
- Total is 3.3m (3,298,080 words = 1,957,499 British + 1,340,581 American)
- For distribution of both files and words in spreadsheet form see under Documentation
{kind=link}
The word counts tabulated above refer to the XML and plain text versions available at consortium universities. Counts in online versions can be up to 15% higher because they measure tokens rather than words: thus the single words don’t, she’s, we’ve, they’d and John’s each count as two tokens, since the contracted negative, contracted verbs and the possessive suffix ‘s are counted as tokens for tagging purposes. Punctuation marks are tokens too. Note that the online software search engines makes it easy to see normalised frequencies overall and by genre.
Mark-up
The master-copy of the ARCHER corpus is now fully XML-compliant (Zurich) and with TEI-compliant headers (Zurich/Manchester). The following versions are available at consortium universities: XML (UTF-8 character set) and plain text (Latin-1). The version of the XML files currently online at Lancaster can be searched with CQPweb software. Coming soon is a CQPweb version tagged with the CLAWS-6 tagset (Lancaster/Leicester) after normalisation of spelling with Alistair Baron’s VARD 2 program (Lancaster/Freiburg). Another online version, VARDed and tagged with the Treebank tagset and parsed with a dependency parser (Zurich), is expected to follow shortly afterwards.
ARCHER is essentially an original-spelling corpus, albeit the spelling of published editions. All versions share the same text and bibliographic and non-linguistic mark-up, but future online versions at Lancaster and at Zurich will differ in their linguistic mark-up.
Correction
There has been a great deal of work to improve the accuracy of the corpus text, the bibliographic documentation (Manchester) and the consistency of file structure and mark-up (Manchester/Zurich). Some files up to version 3.1 had sporadically normalised spellings, with the spelling as it appeared in the edition inserted in a comment; in version 3.2 it is always the edition’s spelling which appears in the main text. We have attempted to mark speakers in fiction and characters in drama consistently (Zurich).
Compilation of new texts
Some text from versions 1 and 2 which had to be excluded from version 3.1 have now been restored, and consortium members have contributed new texts to help fill remaining gaps in coverage in national varieties, genres and periods. Note that some letters are included in 3.2 from writers who are not published authors. Team locations specify where the bulk of the work was carried out, even if members have since moved.
| Variety | Genre | Period | Team |
|---|---|---|---|
| British | advertising | 1750-1999 | Freiburg-Heidelberg/Manchester |
| British | diaries | 1650-1999 | Manchester |
| British | drama | 1600-49 | Freiburg (v2) |
| British | early prose | 1600-49 | Freiburg (v2) |
| British | journals | 1650-1999 | Manchester |
| British | legal | 1600-1999 | Santiago |
| British | letters | 1650-99, 1700-49, 1750-99 | Uppsala/Helsinki/Freiburg |
| British | sermons | 1650-1999 | Zurich/Manchester |
| American | advertising | 1750-1999 | Freiburg (v2) |
| American | diaries | 1650-1999 | Manchester |
| American | drama | 1800-49, 1900-49 | Uppsala/Helsinki (v2) |
| American | fiction | 1800-49, 1900-49 | Uppsala/Helsinki (v2) |
| American | journals | 1650-1999 | Manchester/Bamberg |
| American | legal | 1750-99 | NAU & USC (v1) |
| American | letters | 1750-99 1800-49 | Uppsala/Helsinki/Freiburg Bamberg |
| American | news | 1800-49, 1900-49 | Uppsala/Helsinki (v2) |
| American | science | 1800-49, 1900-49, 1950-99 | Michigan |
| American | sermons | 1750-99, 1850-99, 1950-99 | Zurich |
The following consortium teams have made further contributions:
- Freiburg: VARDing
- Lancaster: VARDing, POS-tagging, CQPweb
- Leicester: POS-tagging
- Manchester: database management; documentation; text revision and annotation; design of TEI headers
- Trier: word count and word list scripts
- Zurich: XML-compliant format in text and headers; consistency of mark-up; tagged and parsed version
The ARCHER team would like to gratefully acknowledge the contribution of former research members: Marianne Hundt (Zurich, until November 2013), Arja Nurmi (Helsinki, until July 2012), Anna Rosen (Bamberg, until October 2011), Richard W. Bailey (Michigan, †2011), Chris Palmer (Michigan, until 2010). We are also very grateful to various research assistants at the consortium departments: Ole Schützler at Bamberg; Michael Percillier at Freiburg; Tuula Chezek at Helsinki; Lauri Hiltunen and Marije van Hattum at Manchester; Taryn Hakala at Michigan; assistants in the VLCG research group at Santiago de Compostela under the coordination of Paula Rodríguez-Puente; Moira Kindlimann and Pius Meyer at Zurich; Melanie Röthlisberger at Manchester and Zurich.
ARCHER 3.3
The project is continuing with the aim of further improving the corpus.
- Fiction texts will have mark-up for individual speakers and to distinguish direct speech from narration (Santiago).
- We are exploring the possibility of a parallel-text version in which users could switch between original spelling and normalised, present-day spelling.
Additions
There are some natural limitations to material available in some genres in early periods, but two gaps in American coverage should be filled in version 3.3, as shown:
| Variety | Genre | Period | Team |
|---|---|---|---|
| British | all except d, p, l | 1600-49 | diaries and journals at Manchester |
| British | advertising | before 1750 | |
| American | all | before 1750 | |
| American | medicine | 1800-49, 1900-49 | Michigan |
| American | sermons | 1800-49 1900-49 | Manchester Manchester and Bamberg |
Genres: a = advertising, d = drama, f = fiction, h = sermons, j = journals, l = legal, m = medicine, n = news, p = early prose, s = science, x = letters, y = diaries.
Corrections
We are compiling a list of errors in version 3.2 for correction in ARCHER 3.3. Please notify us of possible items by an email to archer@manchester.ac.uk with the subject header ‘ARCHER text correction’.